
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Git
- XCOM
- AWS
- SecretsManager
- ci/cd
- S3
- kinesis
- sqs
- github actions
- authoring
- DAG
- Task
- TaskFlow
- dagrun
- Scheduling
- pipeline
- testing
- credentials
- RDS
- boto3
- airflow
- dynamic task mapping
- Operator
- Data Firehose
- celery
- Concept
- lambda
- git book
- executor
- mysql
- Today
- Total
CS
Airflow: DAG 본문
Airflow DAGs 문서에 따라 DAG를 알아보겠습니다.
- DAG 정의
- Task 의존성
- DAG 불러오기
- DAG 실행
- DAG에 연결
- Default Arguments
- Flow 제어
- DAG 시각화
- TaskGroup
- DAG & Task 설명문
- SubDAG
- TaskGroup과 SubDAG
- DAG 패키징
- .airflowignore
- DAG pausing, deactivation, deletion
DAG (Directed Acyclic Graph)는 Airflow의 핵심으로, Task를 모아 의존성과 관계에 따라 정렬하여 어떻게 실행되어야 하는지 밝힙니다. 또한 대부분의 경우 "내일부터 5분마다" 혹은 "2023년 1월 1일부터 매일" 등 실행 스케쥴을 정합니다.
DAG 자체는 실제로 어떤 작업을 실행하는지에는 관여하지 않습니다. 작업 순서, 재시도 횟수, 시간 제한 등 어떻게 실행할 것인지만 다룹니다.
DAG 정의
세 가지 방법으로 DAG를 정의할 수 있습니다.
import datetime
from airflow import DAG
from airflow.operators.empty import EmptyOperator
## 1. context manager
with DAG(
dag_id="my_dag",
start_date=datetime.datetime(2023, 1, 1),
schedule="@daily",
):
EmptyOperator(task_id="my_task")
## 2. standard constructor
my_dag = DAG(
dag_id="my_dag",
start_date=datetime.datetime(2023, 1, 1),
schedule="@daily",
)
# 오퍼레이터에 DAG 전달
EmptyOperator(task_id="my_task", dag=my_dag)
## 3. @dag decorator
# DAG 함수 정의
@dag(
start_date=datetime.datetime(2023, 1, 1),
schedule="@daily"
)
def my_dag():
EmptyOperator(task_id="my_task")
# DAG 객체 생성
my_dag()
Task 의존성
보통 Task/오퍼레이터는 외따로 존재하지 않고, 다른 task에 의존하거나(upstream) 의존됩니다(downstream).
Task 간 의존성을 정의하는 게 DAG 구조(그래프의 엣지)를 만드는 일입니다.
Task 의존성을 정의하는 방법은 크게 두 가지가 있습니다.
## 1. >>와 << (추천)
first_task >> [second_task, third_task]
third_task << fourth_task
## 2. set_upstream과 set_downstream
first_task.set_downstream(second_task, third_task)
third_task.set_upstream(fourth_task)더 복잡한 의존성을 표현할 수도 있습니다.
## task 리스트 간 의존성: cross_downstream
from airflow.models.baseoperator import cross_downstream
# [t1, t2] >> t3
# [t1, t2] >> t4
cross_downstream([t1, t2], [t3, t4])
## 사슬 구조 연결: chain
from airflow.models.baseoperator import chain
# t1 >> t2 >> t3 >> t4
chain(t1, t2, t3, t4)
# 동적으로도 가능
chain(*[EmptyOperator(task_id='t' + i) for i in range(1, 6)])
# 같은 크기의 task 리스트의 쌍끼리 의존성
# t1 >> t2 >> t4 >> t6
# t1 >> t3 >> t5 >> t6
chain(t1, [t2, t3], [t4, t5], t6) # cross_downstream과 구별에 주의
DAG 불러오기
Airflow는 DAG_FOLDER에 있는 파이썬 파일을 실행하여 그 파일 안에 있는 DAG를 불러옵니다.
하나의 파이썬 파일에 여러 DAG를 정의할 수도, 하나의 DAG를 여러 파이썬 파일에 걸쳐(import 사용) 정의할 수도 있습니다.
다만 Airflow는 파이썬 파일에서 top level에 있는 DAG 인스턴스만 DAG로서 불러오는 점을 유의해야 합니다.
dag_1 = DAG('이 DAG는 불러와짐')
def dag_func():
dag_2 = DAG('이 DAG는 불러와지지 않음')
dag_func()참고로 Airflow는 DAG_FOLDER에서 'airflow'와 'dag'라는 문자열이 포함된 파이썬 파일만 봅니다. 구성 파일에서 DAG_DISCOVERY_SAFE_MODE 옵션을 꺼서 모든 파이썬 파일을 확인하도록 변경할 수 있습니다.
DAG 실행
DAG는
- manually 또는 API를 통해 트리거되거나
- schedule에 정의된 대로
실행됩니다.
DAG에 schedule을 반드시 지정할 필요는 없지만 Airflow 사용 목적상 대부분 정하게 됩니다.
schedule은 DAG 생성 시 인수로 넣으면 됩니다.
## Cron presets
# https://airflow.apache.org/docs/apache-airflow/2.7.0/core-concepts/dag-run.html#cron-presets
# 매일(0시 0분)
with DAG("daily_dag", schedule="@daily"):
...
## Crontab
# 매일 0시 0분
with DAG("daily_dag", schedule="0 0 * * *"):
...또한 Timetable 객체를 사용하면 보다 다양한 schedule을 만들 수 있습니다.
DAG를 실행할 때마다 DAG Run이라는 DAG의 인스턴스가 생성 및 실행됩니다. 동일한 DAG에 대해 동시에 여러 DAG run이 실행될 수 있고, 각각은 다른 data interval을 가질 수 있습니다. data interval은 task가 처리할 데이터의 시간적 범위를 의미합니다.
이러한 메커니즘은 예를 들어 DAG 생성 이전 3개월 동안의 데이터를 처리하는 daily 작업에서 backfill을 실행할 경우, DAG run 약 90개를 한 번에 동시에 실행할 수 있다는 점에서 유용합니다. 이 DAG run들은 실질적으로 동일한 날에 실행되는 거지만, 각각 하루치의 data interval를 대상으로 task를 실행합니다.
Task 역시 Task Instance라는 Task의 인스턴스로서 작동됩니다.
DAG Run은 시작 시점과 종료 시점을 갖습니다. 이는 DAG Run이 실제로 실행되거나 실행을 끝낸 시점을 가리킵니다. 이 또한 start date와 end date라고 부를 수 있는데, DAG의 start date 및 end date와 다른 개념이므로 유의해야 합니다.
그리고 logical date라는 또 다른 날짜가 있는데, 이는 DAG run이 schedule되거나 트리거되는 예정된 시점을 말합니다. 왜 logical이라고 부르냐면 DAG run이 실제로 실행되는 날짜가 아니며 DAG run에서 추상적인 여러 의미를 갖기 때문입니다.
예를 들면 DAG run이 사용자에 의해 트리거되었을 때 logical date는 트리거된 시점이며 이는 DAG run의 시작 시점과 동일합니다. 반면 DAG가 schedule에 의해 실행되었을 때 logical date는 data interval의 시작점이고 DAG run의 시작 시점은 logical date + scheduled interval, 즉 해당 data interval의 종료점입니다.
DAG에 연결
오퍼레이터(Task)를 실행하려면 반드시 DAG에 연결해야 합니다.
오퍼레이터의 파라미터 dag에 연결할 DAG를 기재하는 명시적 방법 외에
with 문 안에 오퍼레이터를 정의하거나,
@dag 데코레이터를 붙인 함수 안에 오퍼레이터를 정의하거나,
이미 DAG와 연결한 다른 오퍼레이터의 upstream 또는 downstream에 오퍼레이터를 붙이는 방법이 있습니다.
Default Arguments (default_args) 인수에 기본 값 설정
대부분의 경우, 한 DAG에 속한 오퍼레이터들에게는 인수(retries 등)에 동일한 값을 사용합니다.
이때 각 오퍼레이터마다 인수를 입력할 필요 없이 DAG에만 인수를 주면 자동적으로 해당 DAG에 속한 모든 오퍼레이터에 적용됩니다.
import pendulum
with DAG(
dag_id="my_dag",
start_date=pendulum.datetime(2016, 1, 1),
schedule="@daily",
# DAG에 기본 인수 retries 입력
default_args={"retries": 2},
):
op = BashOperator(task_id="hello_world", bash_command="Hello World!")
print(op.retries) # 2
Flow 제어
기본적으로 DAG에서는 upstream이 모두 성공한 Task만 실행됩니다. 이에 대한 옵션이 여러가지 있습니다.
- Branching 가지치기: 조건을 달아 그에 해당하는 Task를 실행합니다.
- Trigger Rules: upstream 모두 성공/실패 등 Task 실행 조건을 정합니다.
- Setup and Teardown: setup and teardown(작업 전 자원을 확보하고 작업 후 자원을 해제하는 작업)에서 teardown task에 setup task가 성공하였을 때만 실행되도록 할 수 있습니다.
- Latest Only: branching의 특별한 형태로, data interval이 현재인 경우(최신 작업)에만 task를 실행합니다.
- Depends On Past: 해당 task의 이전 실행의 결과에 따라 task를 실행합니다.
Branching
말 그대로 가지(그래프의 엣지)를 여러 개 만들어서 조건에 따라 특정 가지(들)로만 진행하는 방식입니다.
@task.branch 데코레이터로 생성할 수 있습니다.
@task.branch는 @task와 비슷하지만 붙는 함수가 다른 task ID(혹은 ID 리스트)를 반환해야 한다는 점이 다릅니다. branch task의 바로 downstream에 있는 task 중에서만 가능합니다. 특정 task가 선택되면 다른 가지에 있는 task는 스킵됩니다. 또한 None을 반환하여 모든 downstream task를 스킵할 수도 있습니다.

다만 선택되지 않은 가지에 있는 task가 스킵되지 않는 경우도 있습니다. 위에서 branch task는 branch_a로 향하는데, join은 선택되지 않은 가지에 있지만 동시에 선택된 가지에도 있기 때문에 follow_branch_a 실행 후 실행됩니다.
@task.branch는 XComs을 통해 upstream task에 기반한 동적 branching을 할 수 있습니다.
start_op = BashOperator(
task_id="start_task",
# xcom으로 5가 전달됨
bash_command="echo 5",
xcom_push=True,
dag=dag,
)
@task.branch(task_id="branch_task")
# task instance를 받음
def branch_func(ti=None):
# strat_task의 xcom 획득
xcom_value = int(ti.xcom_pull(task_ids="start_task"))
if xcom_value >= 5:
return "continue_task"
elif xcom_value >= 3:
return "stop_task"
else:
return None
branch_op = branch_func()
continue_op = EmptyOperator(task_id="continue_task", dag=dag)
stop_op = EmptyOperator(task_id="stop_task", dag=dag)
# branching의 의존성 표시 형식
start_op >> branch_op >> [continue_op, stop_op]자작 오퍼레이터를 사용해 branching을 하고 싶으면 BaseBranchOperator를 상속하여 choose_branch 메소드를 구현하면 됩니다.
from airflow.operators.branch import BaseBranchOperator
class MyBranchOperator(BaseBranchOperator):
def choose_branch(self, context):
"""
달의 첫 날에만 추가 작업 수행
"""
if context['data_interval_start'].day == 1:
return ['daily_task_id', 'monthly_task_id']
elif context['data_interval_start'].day == 2:
return 'daily_task_id'
else:
return None참고로 Airflow는 BranchPythonOperator보다 @task.branch를 사용하는 것을 추천합니다. BranchPythonOperator는 자작 오퍼레이터를 구현할 때만 사용하는 게 좋습니다.
Latest Only
DAG Run은 backfill 등 현재가 아닌 날짜를 대상으로 실행되는 경우가 꽤 있습니다. 과거를 대상으로 하는 작업에서는 실행하고 싶지 않은 task가 DAG에 있는 경우 LatestOnlyOperator을 사용할 수 있습니다.
이 오퍼레이터의 downstream에 있는 task는 '최신' DAG run이 아닌 경우 모두 스킵됩니다. 여기서 최신이란 현재 시간이 DAG run 실행 시간과 예정된 다음 DAG run 실행 시간 사이에 있으며 외부적으로 트리거된 실행이 아닌 경우를 말합니다.
latest_only = LatestOnlyOperator(task_id="latest_only")
t1 = EmptyOperator(task_id="task1")
t2 = EmptyOperator(task_id="task2")
t3 = EmptyOperator(task_id="task3")
t4 = EmptyOperator(task_id="task4", trigger_rule=TriggerRule.ALL_DONE)
latest_only >> task1 >> [task3, task4]
task2 >> [task3, task4]위 DAG run이 최신이 아닐 때
- task1: latest_only의 바로 downstream에 있으므로 스킵
- task2: latest_only와 상관 없으므로 실행
- task3: task1은 스킵, task2는 실패인데 기본 trigger rule은 all_success이므로 스킵
- task4: task3과 동일한 상황인데 trigger rule을 all_done으로 하였으므로 실행
Depends On Past
이전 DAG run에서 성공한 task만 실행하고 싶은 경우 task의 depends_on_past 파라미터를 True로 설정하면 됩니다. DAG가 최초로 실행되는 경우 해당 task는 실행됩니다.
Trigger Rules
기본적으로 upstream task가 모두 성공(all_success)해야만 task를 실행합니다. task의 trigger_rule 파라미터를 통해 이를 변경할 수 있습니다. trigger_rule 종류는 Airflow 문서에서 확인하세요.
branching을 사용할 때 여러 가지가 거치는 task가 있다면 trigger rule을 잘 설정해야 합니다. 기본 값인 all_sucess인 경우 upstream에 스킵된 task가 있다면 해당 task 역시 스킵되기 때문입니다. 이런 상황에서는 upstream에 실패한 task가 없고 하나 이상의 성공한 task가 있으면 실행되는 none_failed_min_one_success를 사용하는 게 의도에 부합할 것입니다.
DAG 시각화
DAG를 시각적으로 보려면 Airflow UI를 사용하는 게 좋습니다. 원하는 DAG를 누른 후 "Graph" 탭에서 볼 수 있습니다. task instances의 상태를 확인할 수 있습니다.
복잡한 DAG를 다룰 때 더 쉽게 볼 수 있는 방법들이 있습니다.
TaskGroup
TaskGroup은 말 그대로 task를 묶는 것입니다. 비슷한 기능인 SubDAG와 다르게 TaskGroup은 UI 외의 변화는 전혀 없습니다. TaskGroup 내 task은 여전히 해당 DAG에 존재하고, DAG의 설정과 pool 구성을 따릅니다.

from airflow.decorators import task_group
@task_group()
def group1():
task1 = EmptyOperator(task_id="task1")
task2 = EmptyOperator(task_id="task2")
task3 = EmptyOperator(task_id="task3")
group1() >> task3task1과 task2는 group1에 속하고 group1이 task3의 upstream이 되므로, task1과 task2는 task3의 upstream인 것입니다.
with DAG(
dag_id="dag1",
start_date=datetime.datetime(2016, 1, 1),
schedule="@daily",
# DAG 기본 인수로 retries=1
default_args={"retries": 1},
):
# TaskGroup 기본 인수로 retries=3
@task_group(default_args={"retries": 3})
def group1():
"""docstring은 Airflow UI에서 TaskGroup의 툴팁이 됨"""
task1 = EmptyOperator(task_id="task1")
# Task 인수로 retries=2
task2 = BashOperator(task_id="task2", bash_command="echo Hello World!", retries=2)
print(task1.retries) # 3
print(task2.retries) # 2TaskGroup 단위로 default_args를 정하면 DAG의 default_args를 덮어쓸 수 있습니다.
기본적으로 TaskGroup 내에 있는 task(자식 task)의 ID는 TaskGroup의 ID가 접두사로 붙습니다. 이는 DAG에서 고유성을 확보하기 위함입니다. 이를 비활성화하려면 TaskGroup의 파라미터 prefix_group_id에 False를 주어야 합니다. 비활성화한 경우 고유성에 신경 써야 합니다.
Edge Label
Airflow UI에서 task 간 엣지에 설명 문자열을 달 수 있습니다. 특히 branching을 쓸 때 조건을 기재할 수 있어 유용합니다.
from airflow.utils.edgemodifier import Label
my_task >> Label("When empty") >> other_task
# or
my_task.set_downstream(other_task, Label("When empty"))
DAG & Task 설명문
Airflow UI에서 DAG와 task에 설명을 달 수 있습니다.
json, yaml 등 여러 종류가 있는데 DAG에는 markdown인 doc_md만 붙일 수 있습니다.
DAG/task의 속성 doc_md에 직접 문자열로 쓰거나 템플릿 파일을 입력할 수 있습니다.
템플릿 파일의 경우 '.md'로 끝나는 문자열을 입력해야 합니다. 상대 주소를 쓸 경우 해당 DAG 파일이 있는 폴더에서 시작합니다. 해당 위치에 템플릿 파일이 없으면 jinja2.exceptions.TemplateNotFound 예외가 발생합니다.
t = BashOperator("foo", dag=dag)
t.doc_md = """\
#Title"
Here's a [url](www.airbnb.com)
"""
SubDAG
여러 개의 task를 여러 DAG에서 똑같이 사용하거나, 여러 task를 하나의 논리적 단위로 묶고 싶을 때 SubDAG를 사용할 수 있습니다.
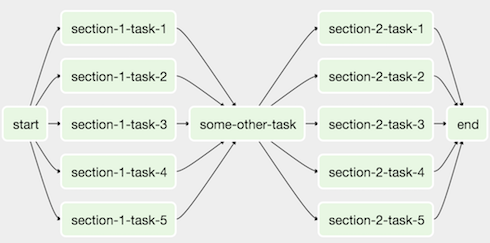
이 구조를

이렇게 바꿀 수 있습니다.
SubDAG는 SubDagOperator에 DAG 객체를 생성하는 함수를 넣어 만들 수 있습니다. 왜 DAG 객체를 바로 넣지 않고 DAG 객체를 생성하는 함수를 넣냐면, SubDAG가 개별적인 DAG로 인식되지 않게 하기 위해서로, Airflow는 파이썬 파일의 top level에 있는 DAG를 개별적인 DAG로 불러오기 때문입니다.
SubDAG를 생성하는 함수는 다음처럼 만들 수 있습니다.
def subdag(parent_dag_name, child_dag_name, args) -> DAG:
"""
subdag용 DAG 생성
:param str parent_dag_name: 부모 DAG ID
:param str child_dag_name: 자식 DAG ID
:param dict args: subdag 기본 인수
:return: subdag로 쓸 DAG
"""
dag_subdag = DAG(
dag_id=f"{parent_dag_name}.{child_dag_name}",
default_args=args,
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
schedule="@daily",
)
for i in range(5):
EmptyOperator(
task_id=f"{child_dag_name}-task-{i + 1}",
default_args=args,
dag=dag_subdag,
)
return dag_subdag메인 DAG 파일에서 다음처럼 사용합니다.
from airflow.operators.subdag import SubDagOperator
DAG_NAME = "example_subdag_operator"
with DAG(
dag_id=DAG_NAME,
default_args={"retries": 2},
start_date=datetime.datetime(2022, 1, 1),
schedule="@once",
tags=["example"],
) as dag:
start = EmptyOperator(task_id="start",)
section_1 = SubDagOperator(
task_id="section-1",
subdag=subdag(DAG_NAME, "section-1", dag.default_args),
)
some_other_task = EmptyOperator(task_id="some-other-task",)
section_2 = SubDagOperator(
task_id="section-2",
subdag=subdag(DAG_NAME, "section-2", dag.default_args),
)
end = EmptyOperator(task_id="end",)
start >> section_1 >> some_other_task >> section_2 >> endAirflow UI에서 SubDagOperator를 클릭해 내부 task를 확인할 수 있습니다.
SubDAG를 사용할 때 유의점
- SubDAG의 dag_id는 부모 DAG ID를 접두사로 기재하는 parent.child로 짓는 게 관습입니다.
- SubDAG에 메인 DAG의 인수를 줄 수 있습니다(위 예시처럼).
- SubDAG는 반드시 schedule을 가지고 활성화되어야 합니다. 만약 SubDAG의 schedule이 None 또는 @once라면, SubDAG는 아무 것도 하지 않은 채로 성공하기만 할 것입니다.
- SubDagOperator를 clear하면 내부 task도 모두 clear됩니다.
- SubDagOperator를 success 처리하는 것은 내부 task에 영향을 주지 않습니다.
- 내부 task에 depends on past를 사용하면 복잡해집니다.
- SubDAG에 따로 executor를 지정할 수 있는데, SequentialExecutor를 사용하면 효과적으로 parallelism을 통제할 수 있습니다. parallelism은 Airflow에서 동시에 실행될 수 있는 task 수를 말하고 기본 값은 32입니다. SubDagOperator는 parallelism을 신경쓰지 않기 때문에 주의해야 합니다. LocalExecutor를 쓰면 여러 task를 한 슬롯에서 실행하여 worker를 초과 구독할 수 있습니다.
TaskGroup과 SubDAG
SubDAG는 TaskGroup과 비슷하지만 성능과 기능적 문제를 발생시킬 수 있습니다.
- Backfill시, Sub parallelism을 무시하므로 worker를 초과 구독할 수 있습니다.
- SubDAG는 그 자체의 DAG 속성을 갖습니다. SubDAG의 속성이 부모 DAG와 다르면 의도치 않은 동작이 발생할 수 있습니다.
- SubDAG는 하나의 완전한 DAG이기 때문에 메인 DAG를 한 번에 볼 수 없습니다.
반면 TaskGroup은 순전히 UI용 그룹 개념이므로 더 나은 옵션입니다. TaskGroup 내 task는 TaskGroup 밖 task와 동일하게 동작합니다.
DAG 패키징
간단한 DAG는 하나의 파이썬 파일로 가능하지만, 복잡한 DAG는 여러 파일에 나누어 존재할 수 있습니다. 이 파일들을 그냥 DAG_FOLDER에 모아 놓을 수도 있지만, zip 파일로 패키징할 수도 있습니다. 예를 들어 2개의 DAG 파일과 의존성 파일 하나를 패키징할 수 있습니다.
my_dag1.py
my_dag2.py
package1/__init__.py
package2/functions.py여기에는 주의사항이 있습니다.
- pickling하면 사용할 수 없습니다.
- 컴파일된 라이브러리는 포함할 수 없습니다.
- Airflow는 해당 디렉토리를 파이썬의 sys.path에 넣어 임포트할 수 있게 만드므로, 패키지 이름이 이미 존재하는 패키지 이름과 겹치지 않도록 해야 합니다.
컴파일된 의존성과 모듈을 사용해야 한다면 파이썬의 virtualenv 시스템을 쓰는 게 좋습니다.
.airflowignore
DAG_FOLDER나 PLUGINS_FOLDER에 있는 특정 파이썬 파일을 무시하고 싶다면 .airflowignore 파일을 만들 수 있습니다. .airflowignore 파일을 생성해 파일의 이름이나 패턴을 입력하여 저장하면 Airflow는 해당하는 파일을 읽지 않습니다.
패턴 문법은 regexp와 glob을 사용할 수 있는데, 구성 파일의 DAG_IGNORE_FILE_SYNTAX로 설정할 수 있습니다. 기본 값은 regexp입니다.
만약 .airflowignore가 다음과 같다면
project_a
tenant_[\d]
다음 파일들이 무시될 수 있습니다.
project_a_dag_1.py
TESTING_project_a.py
tenant_1.py
project_a/dag_1.py
tenant_1/dag_1.py파일뿐만 아니라 디렉토리도 패턴에 걸리며, 걸릴 경우 해당 디렉토리의 하위 파일 및 디렉토리가 모두 무시된다는 점을 유의해야 합니다.
.airflowignore는 DAG_FOLDER 바로 아래가 아니라 하위 디렉토리에도 만들 수 있는데, 이러면 그 디렉토리에만 적용됩니다.
DAG pausing(정지), deactivation(비활성화), deletion(삭제)
DAG가 실행되지 않는 상태는 여러가지 있습니다. pause, deactivate, DAG에 대한 메타데이터가 모두 삭제되는 상황입니다.
Pause 정지
DAG_FOLDER에 존재하는 DAG는 UI에서 pause될 수 있습니다. pause된 DAG는 schedule되지 않지만 UI에서 트리거할 수 있습니다. pause된 DAG는 UI의 'Pause' 탭에서 볼 수 있고, pause되지 않은 DAG는 'Active' 탭에서 볼 수 있습니다(즉 un-pause를 의미).
Deactivate 비활성화
UI의 'Active'와는 다른 개념으로, DAG는 deactivate될 수 있습니다. scheduler가 DAG_FOLDER를 검사할 때 전에 존재하여 데이터베이스에 등록되어 있으나 지금은 존재하지 않는 DAG는 deactivate합니다. DAG의 메타데이터나 기록은 여전히 남아 있고 다시 DAG_FOLDER에 DAG가 확인되면 DAG를 activate하고 기록을 볼 수 있습니다.
이 과정은 UI나 API를 통해서는 불가능하고 DAG_FOLDER에서 해당 DAG가 담긴 파일을 제거하는 것으로만 가능합니다. deactivate된 DAG는 UI에서 볼 수 없습니다. 가끔 DAG 기록이 나타날 수도 있으나 정보를 보려고 하면 오류가 발생할 것입니다.
Delete 삭제
UI나 API를 통해서 메타데이터 데이터베이스에 있는 DAG 메타데이터를 삭제할 수 있습니다. 하지만 삭제해도 UI에서 DAG가 사라지지 않을 수 있습니다. DAG가 DAG_FOLDER에 존재하면 scheduler가 폴더를 검사할 때 다시 나타납니다. DAG 기록만 삭제되는 것입니다.
즉 DAG와 DAG 메타데이터 및 기록을 모두 삭제하고 싶다면 DAG를 pause하고, UI나 API를 통해 메타데이터를 지우고, DAG_FOLDER에서 DAG 파일을 삭제한 후 scheduler가 DAG를 deactivate할 때까지 기다려야 합니다.
'Airflow' 카테고리의 다른 글
| Airflow: Task (0) | 2023.08.24 |
|---|---|
| Airflow: DAG Run (0) | 2023.08.21 |
| Airflow: 구조 개요 (0) | 2023.08.17 |
| Airflow: 데이터를 데이터베이스에 적재하고 주기적으로 갱신하는 파이프라인 만들기 (0) | 2023.08.02 |
| Airflow: TaskFlow API의 여러 기능 (0) | 2023.07.23 |


