Airflow: Best Practice 1/3 - DAG 작성
Airflow Best Practices
Best Practices — Airflow Documentation
airflow.apache.org
- Task 작성 시 유의사항
- Task 제거
- Task 간 데이터 전달
- Top level 코드
- 동적 DAG 생성
- DAG 변경 후 트리거
- Trigger rule과 Watcher pattern
- 예외 AirflowClusterPolicySkipDag를 클러스터 정책에서 사용하여 특정 DAG 제외
Task 작성 시 유의사항
Airflow의 task는 데이터베이스에서의 트랜잭션과 동일하게 취급해야 합니다. 이는 task가 불완전한 결과를 도출하지 말아야 한다는 것입니다. 하나의 task는 말 그대로 하나의 작업이 되어야 합니다.
Airflow는 task가 실패할 경우 재시도합니다. 따라서 task는 매 시도마다 동일한 결과를 낼 수 있도록 해야 합니다(멱등성). 다음은 이를 위해 따를 수 있는 몇 가지 사항입니다.
■ SQL의 INSERT문은 시도할 때마다 새로운 열을 만듭니다. 따라서 task에는 UPSERT를 쓰는 게 좋습니다.
■ 특정 시점에 대하여 작업을 수행합니다. 최신 데이터를 대상으로 작업을 수행하는 경우, 재시도 전의 데이터와 재시도하는 당시의 데이터가 다를 수 있습니다. 이를 위해 data_interval_start 값을 사용할 수 있습니다.
■ 파이썬 datetime의 now()는 현재 datetime 객체를 주는데, 이를 task 안에 사용하지 말아야 합니다. 시도마다 다른 결과 값을 생성하게 됩니다. 일시적인 로그를 생성할 때는 사용할 수도 있습니다.
connection_id나 S3 경로처럼 동일한 값을 반복적으로 입력해야 하는 인수의 경우, 각 task마다 입력하는 것보다 DAG의 default_args로 입력하는 게 좋습니다. 오타를 막을 수 있습니다. 또한 대부분의 connection 인수들은 다른 이름을 갖고 있기 때문에, default_args에 전부 적어놓고 써도 됩니다.
Task 제거
DAG에서 task를 제거할 때 주의할 필요가 있습니다.
task를 제거하는 순간 UI에서 해당 task에 대한 기록을 볼 수 없어지기 때문입니다.
Task 간 데이터 전달
Celery executor나 Kubernetes executor를 사용하는 경우 Airflow는 하나의 DAG에 있는 task를 다른 서버에서 실행합니다. 따라서 task를 실행하는데 필요한 데이터나 설정을 로컬로 저장하면 안 됩니다. Local executor를 쓰는 경우에도 권장하지 않습니다.
대신 task 간에 작은 데이터를 전달할 때는 XCom을 사용하고, 큰 데이터를 전달할 때는 S3나 HDFS 같은 외부 저장소를 쓰는 게 좋습니다. 예를 들어, 처리한 데이터를 S3에 저장하는 task가 있다면 S3 경로를 XCom으로 보낼 수 있고, downstream task는 해당 S3 경로를 가져와 S3에 있는 데이터를 가져올 수 있습니다.
또한 task에는 비밀번호나 토큰 같은 인증 값을 저장하지 않는 게 좋습니다. 대신 Airflow의 connection을 사용할 수 있습니다.
Top level 코드
코드의 top level에는 오퍼레이터나 DAG를 명시하는 것 외에 다른 것은 쓰지 않아야 합니다. Airflow scheduler는 DAG 파일을 파싱할 때 top level 코드를 실행하는데, DAG 파싱에 필요 없는 코드가 있으면 성능을 저해하게 됩니다.
scheduler는 오퍼레이터의 execute 메소드 밖에 있는 코드를 Airflow 구성의 min_file_process_interval +a의 간격으로 주기적으로 실행합니다. 이는 DAG를 동적으로 스케줄링하기 위함으로, DAG는 처음 작성된 이후로 그 내용이 변경될 수 있기 때문에 scheduler가 주기적으로 DAG를 검사하여 이미 스케줄된 DAG에 반영하는 것입니다.
특히 데이터베이스 접속은 많은 연산과 네트워킹을 하기 때문에 피해야 합니다.
또한 임포트하는 것은 생각보다 오랜 시간이 걸리기 때문에, 모듈을 사용할 파이썬 함수 내부에서 임포트를 해야 합니다.
# NumPy를 사용하는 task의 경우
@task()
def print_array():
import numpy as np
a = np.arange(15).reshape(3, 5)
print(a)
return a
print_array()위처럼 task 함수 내부에서 모듈을 임포트하는 게 아니라 top level에서 임포트하는 경우, DAG 파일이 파싱될 때마다 임포트가 되어 성능을 저해합니다. 예시의 경우 print_array가 실행될 때만 임포트됩니다.
코드가 Top level인지 확인하기
확실하게 top level에 써 있는 코드뿐만 아니라, 일부 인수도 top level 코드가 됩니다.
파이썬은 파이썬 파일을 파싱할 때 겉으로 보이는 코드(top level)를 실행하고, 안에 있는 코드는 실행하지 않습니다. 이를 이용해 어떤 코드가 top level인지 확인할 수 있습니다.
from airflow import DAG
from airflow.operators.python import PythonOperator
import pendulum
def get_task_id():
print("Executing 1") # top level 확인용
return "print_array_task"
def get_array():
print("Executing 2") # top level 확인용
return [1, 2, 3]
with DAG(
dag_id="example_python_operator",
schedule=None,
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
tags=["example"],
) as dag:
operator = PythonOperator(
task_id=get_task_id(),
python_callable=get_array,
dag=dag,
)다음은 실행 결과입니다.
root@cf85ab34571e:/opt/airflow# python /files/test_python.py
Executing 1get_task_id는 top level이고 get_array는 top level이 아니라는 것을 알 수 있습니다.
Top level과 Airflow 변수
Airflow 변수를 사용하면 네트워크 호출과 데이터베이스 접속을 하므로, 이를 top level에서 두는 것은 최대한 피해야 합니다. 만약 Airflow 변수를 반드시 top level에 두어야 한다면 DAG 파싱을 위해 변수를 로컬에 캐싱하도록 할 수 있습니다. airflow.cfg의 use_cache와 cache_ttl_seconds가 이에 관한 항목입니다. 이 캐시는 DAG를 파싱하는 과정에서만 사용됩니다.
■ use_cache: DAG 파싱를 위해 로컬에 변수를 캐싱합니다. 이를 사용하면 변수를 top level에서 불러와도 파싱 속도에 크게 영향을 주지 않을 수 있습니다. 다만 캐싱을 하기 때문에 변수를 변경한 후 일정 시간이 지나야 반영이 되는 점을 유의해야 합니다. 기본 값은 False입니다.
■ cache_ttl_seconds: use_cache를 사용하는 경우 cache의 유효 기간입니다. 이보다 오래된 항목은 새로 반영됩니다. 즉 변수를 변경한 후 캐시에 반영될 때까지의 시간을 의미합니다. 기본 값은 900입니다.
오퍼레이터의 execute 메소드 안에서는 변수를 마음대로 사용해도 됩니다(TaskFlow의 @task 데코레이터를 단 함수 내부도 해당합니다.). 또한 오퍼레이터에 Jinja 템플릿을 통해 변수를 전달할 수도 있습니다. 이 또한 task가 실행될 때까지 변수를 불러오지 않습니다.
민감한 데이터인 경우 변수 대신 secret backend를 쓰는 게 좋습니다.
Top level과 Timetable
Timetable 코드의 top level에 Airflow 변수나 connection 또는 데이터베이스 접속을 사용하지 말아야 합니다. 여기에는 timetable의 __init__ 인수에서 그러한 값들을 불러오는 것도 포함됩니다.
# 나쁜 예시
class CustomTimetable(CronDataIntervalTimetable):
def __init__(self, *args, something=Variable.get("something"), **kwargs):
self._something = something
super().__init__(*args, **kwargs)
# 좋은 예시
class CustomTimetable(CronDataIntervalTimetable):
def __init__(self, *args, something="something", **kwargs):
self._something = Variable.get(something)
super().__init__(*args, **kwargs)
동적 DAG 생성
많은 DAG를 파라미터 정도만 바꿔서 생성해야 하는 경우 동적으로 DAG를 생성하는 게 유용합니다.
위에서 다룬 top level에서의 주의사항이 동적으로 DAG를 생성할 때 특히 중요합니다.
따라서,
- Airflow 변수 대신 환경 변수를 사용하거나,
- DAG 폴더에 메타데이터를 담은 파이썬 파일을 만들어 임포트하거나,
- 메타데이터를 YAML 같은 구조화된 데이터 파일에 담아 불러오는
방식을 통해 동적으로 DAG를 생성할 수 있습니다.
DAG 변경 후 트리거
DAG 파일이나 관련 파일을 변경한 후 바로 DAG를 트리거하지 말아야 합니다.
파일이 변경되면 이를 처리하기 위해 여러 과정을 거칩니다. 우선 scheduler에 의해 파일이 분산됩니다. 그리고 scheduler는 파일을 파싱하고 데이터베이스에 저장합니다. 구성 내용, 파일 시스템 속도, 파일 개수 등에 따라 이러한 과정에 걸리는 시간이 다를 수 있습니다. 아무튼 UI에 DAG가 나타날 때까지 기다린 후 트리거해야 합니다.
이러한 시간에 변화를 주고 싶다면 다음 구성을 변경할 수 있습니다.
■ scheduler_idle_sleep_time: scheduler의 작동 루프에서 할 것이 없었을 경우 다음 작동 루프까지의 간격입니다. 기본 값은 1입니다.
■ min_file_process_interval: DAG 파일 파싱 간격의 최솟값입니다. DAG 변경 사항은 이 간격이 지나야 반영됩니다. 낮게 할수록 CPU 사용량을 늘립니다. 기본 값은 30입니다.
■ dag_dir_list_interval: 새로운 파일을 찾기 위해 DAG 디렉토리를 검사하는 간격입니다. 기본 값은 300입니다.
■ parsing_processes: scheduler가 DAG를 파싱할 때 사용할 수 있는 최대 프로세스 수입니다. 기본 값은 2입니다.
■ file_parsing_sort_mode: scheduler가 DAG 파일을 파싱하는 순서를 정합니다. 기본 값은 modified_time입니다.
- modified_time: 파일 수정 시간으로 정렬합니다. 가장 최근에 수정된 DAG를 우선으로 파싱하고 싶을 때 좋습니다.
- random_seeded_by_host: 여러 scheduler를 사용할 때, scheduler 간에 정렬을 다르게 하지만 host가 같다면 동일한 순서를 갖게 됩니다. 각 scheduler가 다른 DAG를 파싱할 수 있는 HA(고가용성) 모드일 때 유용합니다.
- alphabetical: 파일 이름으로 정렬합니다.
Trigger rule과 Watcher pattern
watcher pattern은 DAG에서 다른 task의 상태를 확인하는 task에 대한 것입니다.
이의 주된 목적은 하나의 task라도 실패한 경우 DAG run을 실패하게 만드는 것입니다.
일반적으로 한 task가 실패하면 downstream task는 실행되지 않고 DAG run은 실패하게 됩니다. 그런데 trigger rule을 변경하게 되면 다른 결과가 발생할 수 있습니다.
예를 들어 teardown task을 두어 trigger rule을 ALL_DONE으로 할 경우, 다른 task와 상관없이 해당 task는 항상 실행됩니다. 이때 DAG run은 해당 task의 상태를 따르게 되므로 다른 task의 상태를 버리게 됩니다. 이러한 경우 watcher pattern이 필요합니다.
watcher task는 다른 task가 실패할 경우 실행되며 항상 실패하는 task입니다. 이를 위해 trigger rule을 ONE_FAILED로 하고 다른 모든 task의 downstream으로 지정해야 합니다. 이렇게 하면 모든 task가 성공할 시 watcher task는 스킵되고, 하나의 task라도 실패할 시 watcher task가 실행되어 실패하고 DAG run도 실패하게 됩니다.
※ trigger rule은 곧바로 upstream인 task에만 적용된다는 점을 유의해야 합니다. 예를 들어 task1 >> task2 >> task3에서 task3의 trigger rule이 ONE_FAILED인 경우, task1가 실패하고 task2가 성공하면 task3는 실행되지 않습니다.
from datetime import datetime
from airflow import DAG
from airflow.decorators import task
from airflow.exceptions import AirflowException
from airflow.operators.bash import BashOperator
from airflow.utils.trigger_rule import TriggerRule
@task(trigger_rule=TriggerRule.ONE_FAILED, retries=0)
def watcher():
raise AirflowException("Failing task because one or more upstream tasks failed.")
with DAG(
dag_id="watcher_example",
schedule="@once",
start_date=datetime(2021, 1, 1),
catchup=False,
) as dag:
failing_task = BashOperator(task_id="failing_task", bash_command="exit 1", retries=0)
passing_task = BashOperator(task_id="passing_task", bash_command="echo passing_task")
teardown = BashOperator(
task_id="teardown",
bash_command="echo teardown",
trigger_rule=TriggerRule.ALL_DONE,
)
failing_task >> passing_task >> teardown
list(dag.tasks) >> watcher()이는 다음 그래프로 표현됩니다.
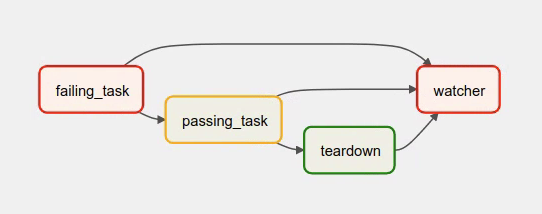
- failing_task는 항상 실패
- passing_task는 항상 성공 (실행될 경우)
- teardown은 항상 실행 (다른 task의 상태와 상관없이) 되며 항상 성공
- watcher는 다른 모든 task의 downstream이며, upstream task가 실패할 시 실행되며 항상 실패하며, 잎 노드이기 때문에 DAG run의 상태를 결정
teardown task 같은, DAG 마지막(잎 노드)에 위치하며 항상 성공하는 task가 없다면 굳이 watcher task를 사용할 필요는 없습니다.
예외 AirflowClusterPolicySkipDag를 클러스터 정책에서 사용하여 특정 DAG 제외
여러 Airflow 클러스터를 다룰 경우 클러스터마다 필요한 DAG를 구분하기 복잡할 수 있습니다. 이때 Airflow의 cluster policy에서 AirflowClusterPolicySkipDag 예외를 사용하여 특정 DAG는 DagBag으로 가져오지 않도록 설정할 수 있습니다.
def dag_policy(dag: DAG):
"""'only_for_beta' 태그를 가진 DAG는 제외"""
if "only_for_beta" in dag.tags:
raise AirflowClusterPolicySkipDag(
f"DAG {dag.dag_id} is not loaded on the production cluster, due to `only_for_beta` tag."
)